
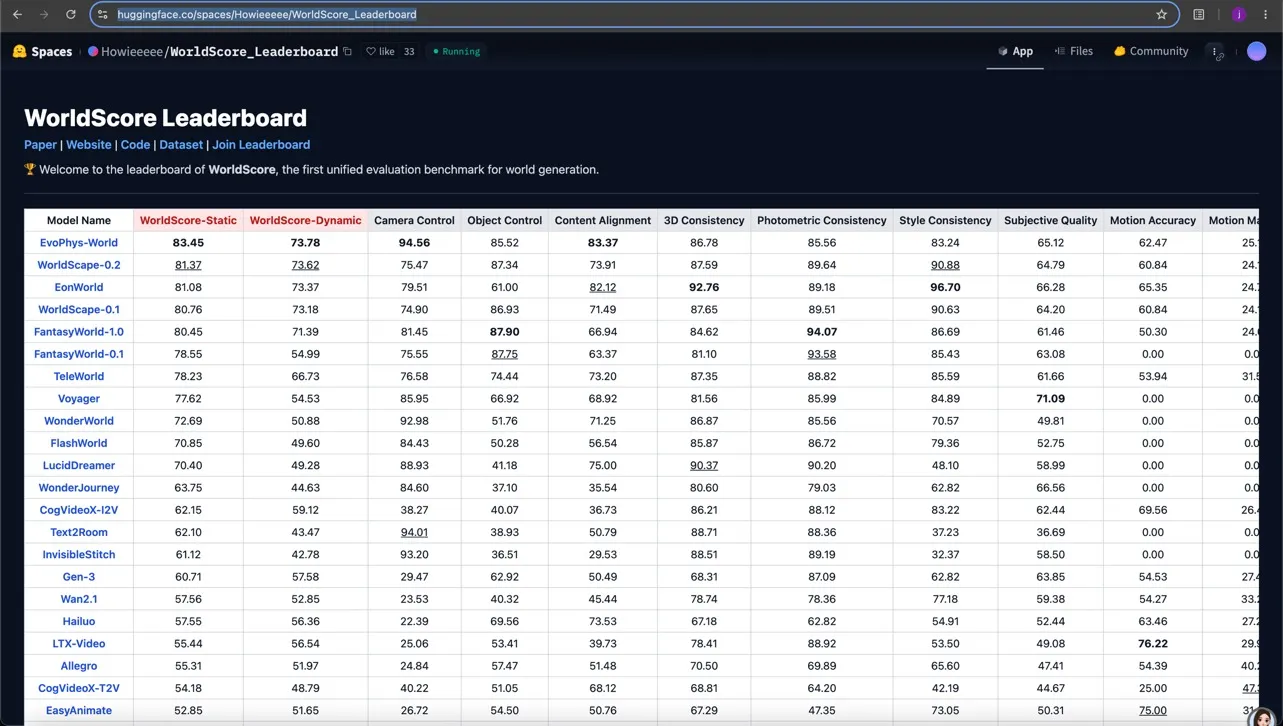
A team at Peking University built a 5D world model called EvoPhys-World and submitted it to Stanford‘s WorldScore benchmark. As of June 8, it ranks first in the “World Generation” category — beating every other model on a leaderboard created by one of America’s top computer science departments.
The model‘s core innovation is moving from “watchable” worlds to “controllable” ones. Instead of just generating a 3D scene you can look at, EvoPhys-World is designed to let you reach in and manipulate objects — picking things up, pushing them around, seeing how they react physically. It’s trained on roughly 40,000 hours of first-person hand-interaction data (typing, grabbing, writing) and uses a dual-engine architecture: a “World Engine” for physics simulation and a “World Policy” for action planning.
WorldScore‘s technical breakdown shows EvoPhys-World excelled at “Camera Control” with a score of 94.56 — meaning it’s unusually good at moving your viewpoint smoothly through a generated scene. That might sound niche, but it‘s a core capability for any immersive simulation, from autonomous driving validation to robot training.
The Hardware Part — This Is the Real Story
The model was trained from scratch on Moore Threads MTT S5000 GPUs. You’ve almost certainly never heard of this company. Moore Threads is a Chinese GPU startup. The MTT S5000 is their flagship AI training card, rated at 1 PetaFlop of FP8 compute with 80GB of HBM memory — specs that sit somewhere between an H100 and a B200.
The team‘s performance data is what makes this genuinely newsworthy. They trained EvoPhys-World on a 160-card cluster (20 nodes) and reported near-linear scaling — 90 percent weak scaling efficiency from 8 to 160 cards. In controlled tests, the Moore Threads cluster matched “international mainstream” GPUs in training throughput. Side-by-side video samples showed nearly identical generation results between the Moore Threads-trained model and a reference model trained on non-Chinese hardware.
A non-CUDA, non-NVIDIA GPU stack just trained a state-of-the-art world model from scratch. That doesn’t mean Moore Threads is about to dethrone NVIDIA. But it does mean the “one GPU ecosystem to rule them all” assumption is starting to crack. For researchers and companies struggling to get H100 allocation, that‘s a signal worth watching.
Why World Models Matter Right Now
If you haven’t been tracking the “world model” space, here‘s the short version. World foundation models are what NVIDIA itself calls the next big thing after LLMs. They don’t just predict the next word in a sentence — they predict what happens next in a physical scene.
For self-driving cars, a world model can simulate a rainy highway so the AI can “practice” without crashing. For humanoid robots, it can simulate a cluttered kitchen so the robot can learn to grab a coffee mug without knocking over everything else. NVIDIA launched its own open Cosmos platform in early 2025 for exactly this purpose.
The fact that a university lab trained a competitive world model on non-NVIDIA hardware — and got it to the top of a Stanford benchmark — is a signal that this field is still wide open. The algorithmic breakthroughs are coming faster than any single vendor can lock them down. If you‘re a researcher without unlimited H100 budgets, that’s good news.
What This Means for the Industry
This isn‘t a “Moore Threads is the next NVIDIA” story. It’s a “foundation model training is becoming more accessible and less ecosystem-locked” story.
Hardware diversification is real. A research group chose an unconventional stack — not because they had to, but because the company‘s “Lighthouse Program” provided the compute. And it worked. The model didn’t just train; it topped a Stanford leaderboard. That suggests the gap between “NVIDIA” and “everything else” is shrinking faster than most people realize.
World model evaluation now has an international yardstick. WorldScore is a Stanford-led initiative, not a Chinese self-assessment. The fact that a non-US team can compete and win on a US-built benchmark means the field is genuinely global. For researchers anywhere, that means clearer standards and better apples-to-apples comparisons.

And the next supply chain debate just got more complicated. If Moore Threads can credibly train SOTA models today, what can they do in two years? The global AI race has multiple supply chains now. And at least one of them just proved it can play at the highest level — not in theory, but with actual leaderboard receipts.
A 5D world model from Peking University topped Stanford‘s WorldScore leaderboard. It was trained on 160 Chinese GPUs most Western researchers have never heard of. The hardware worked. The scaling held. The output quality matched reference models trained on conventional GPUs.
This is not the death of CUDA. It’s not even a close call. But it is the first time a non-NVIDIA stack has produced a leaderboard-topping result in one of AI‘s most competitive emerging fields. For researchers, it’s a proof point that the ecosystem is opening up. For the rest of the industry, it‘s a quiet reminder: the future of AI hardware might not be a single story.
P.S. The next time someone tells you that world models can only be trained on NVIDIA clusters, point them to Stanford’s WorldScore leaderboard and a 160-card Moore Threads setup. It‘s not a coup. But it is a canary — and it’s singing louder than expected.

