
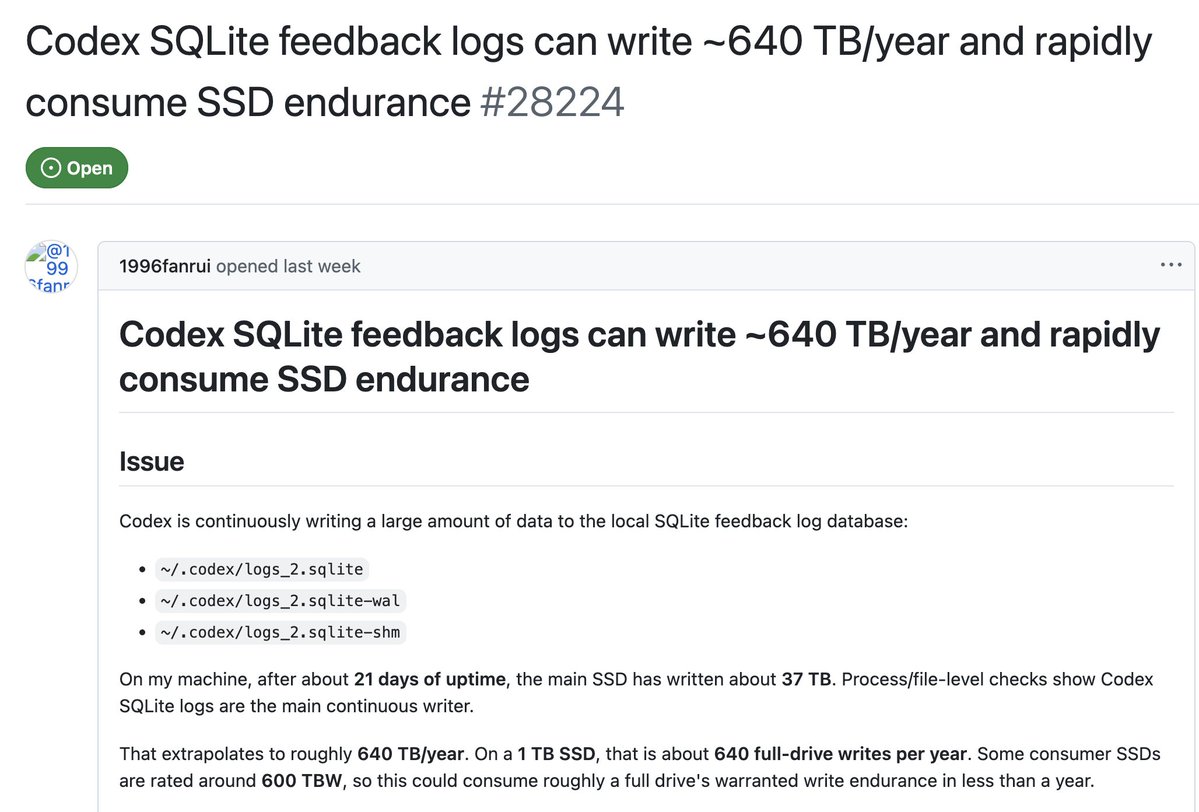
On June 14, a GitHub user named 1996fanrui noticed something wrong with their machine. Disk activity was unusually high. After digging in, they found the culprit: Codex CLI was continuously writing diagnostic logs to a local SQLite database at ~/.codex/logs_2.sqlite
The numbers are staggering. Over 21 days of uptime, the drive had absorbed about 37 TB of writes. Annualized, that‘s roughly 640 TB per year. A typical 1 TB consumer SSD has a Total Bytes Written (TBW) rating of about 600 TB. If left unchecked, this bug could burn through your drive’s entire warrantied lifespan in less than 12 months.

Why It‘s Happening
The root cause is a logging configuration that was probably never meant to reach end users. Codex’s SQLite feedback sink runs at global TRACE level by default — the noisiest possible setting. It logs everything from raw WebSocket payloads to mundane filesystem events like opening system files such as passwd and ld.so.cache.
The software also ignores the standard RUST_LOG environment variable, so there‘s no obvious way to turn it down. Around 71% of the logged data is TRACE-level noise that serves no real diagnostic purpose for most users.
The problem is made worse by write amplification. The database isn’t just growing — it‘s cycling through tens of thousands of insert-and-delete operations per minute. The physical data written to the drive far exceeds the file size you see on disk.

What’s at Stake
For a typical developer using Codex daily, a new drive‘s TBW rating could be exhausted in under a year. This isn’t just a performance issue — it‘s a hardware longevity issue. If you’re running a MacBook or a laptop with soldered storage, replacing the drive isn‘t an option. You’re replacing the entire machine.
Some users have also warned that if the disk fills up completely because of Codex‘s runaway logging, the agent could trigger dangerous file deletions to free up space — potentially removing files unrelated to Codex. That claim hasn’t been confirmed by OpenAI, but it adds another layer of concern for developers running long, automated Codex tasks.
OpenAI‘s Response Status
The issue has been reported since at least April, with multiple tickets filed over the course of the year. OpenAI’s recent changelogs mention some SQLite reliability fixes, but they haven‘t addressed the write rate problem. The GitHub issue remains open.
This isn’t a sophisticated security flaw or a complex architectural problem. It‘s a logging level configuration that someone forgot to change before shipping. The fix is straightforward — lower the log level for end users. But the fact that it’s still unresolved suggests either a lack of urgency or an underestimation of the impact on real users.
P.S. 21 days = 37 TB. 1 year = 640 TB. 1 TB SSD = 600 TBW. Do the math. If you‘re using Codex daily, your drive might be halfway to retirement and you didn’t even notice. OpenAI knows about this. The issue is still open. The question isn‘t whether the bug exists — it’s why it hasn‘t been fixed yet.

