
OpenAI’s internal breakthrough is being treated as a trade secret — the company won’t even tell its own employees how they did it . The results are public: inference costs dropped low enough that unauthenticated ChatGPT traffic could run on hundreds of GPUs instead of thousands . That’s not a discount. That’s a reset.
Nvidia followed with its own move, cutting DeepSeek V4 token costs to one-fifth of launch levels . Two companies, two cost resets, one pattern: the price of running AI just got a lot cheaper, and it happened fast. But the cost per token is no longer the right metric to watch.
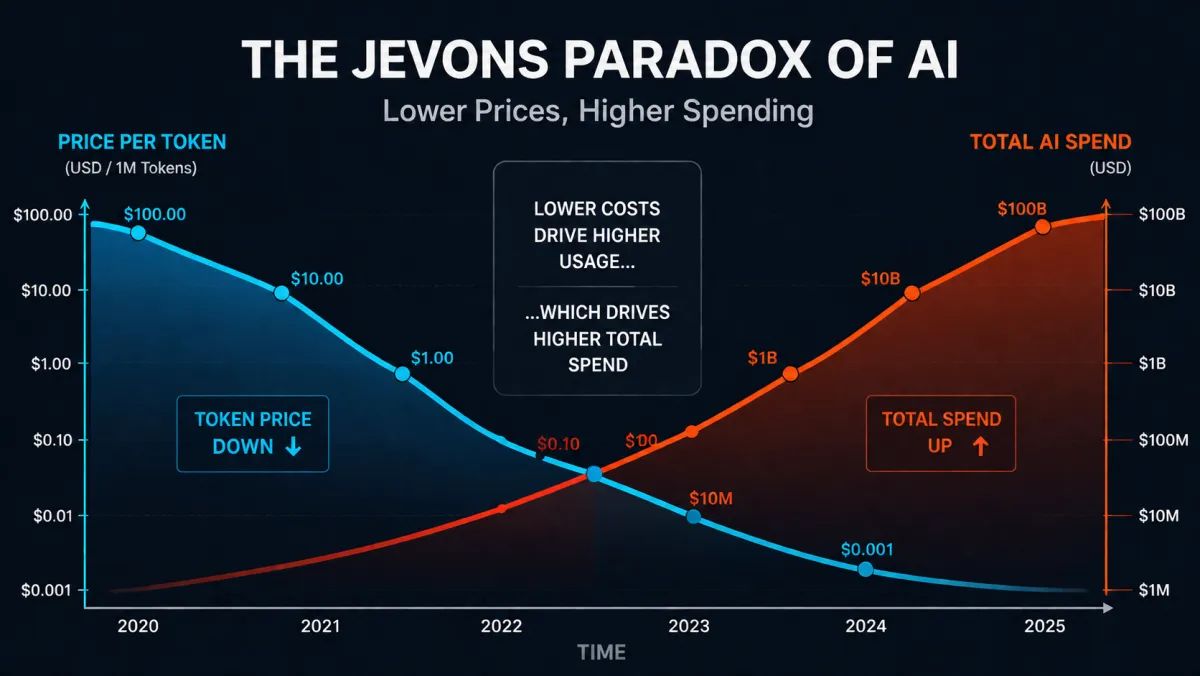
The real metric is total spend. And total spend is climbing.

Jevons Paradox Is Playing Out in Real Time
In 1865, economist William Stanley Jevons observed that when the Watt steam engine made coal use more efficient, coal consumption actually skyrocketed. The same thing is happening with AI .
Token prices have fallen more than 90% since 2023. But total spending on large language models has roughly doubled since late 2025 . While token costs were halved from December 2024 to December 2025, the tokens consumed grew by 450% in the same period .
Apollo Chief Economist Torsten Slok put it directly: “As tokens get cheaper, companies don’t spend less but instead run more AI agents, automate more workflows and generate more code, pushing aggregate expenditure higher even as the unit cost of intelligence collapses” .
This isn’t a pricing problem. It’s a usage problem. And it’s reshaping how companies think about AI economics.
Uber Burned Its Budget by April. That’s the Signal.
For two years, the industry ran on a simple logic: burn capital to build scale, figure out profitability later. That era is ending. Companies are getting serious about the math.
Uber burned through its entire 2026 AI budget by April . The company has now capped monthly AI spending at $1,500 per employee . Microsoft is pulling back on internal Claude Code usage, pushing employees toward cheaper internal options. When the largest companies start rationing AI usage, it’s not because they don’t believe in the technology. It’s because they’re finally doing the math.
The real-world cost of inference is scaling non-linearly. A model that costs $12,000 per month at 10 million queries can approach $90,000 per month at 100 million . Gartner projects inference-led AI spending to nearly double from $9.2 billion in 2025 to $20.6 billion in 2026 . The shift from build costs to run costs is the structural change that most enterprise budgets are not prepared for .
The Pricing War Has Already Started
OpenAI is using its cost advantage to reshape the market. GPT-5.6 Sol beats Claude Mythos on benchmarks and costs half of Fable 5 . DeepSeek is introducing peak/off-peak pricing — 2x during business hours . Nvidia is optimizing its Blackwell platform to push token costs even lower .
The cost curve is bending. But the bill is not shrinking. As Bain & Company analysts put it: “The models get cheaper. The usage gets heavier. The bill stays stubbornly high” .
The Demo Era Is Over. The ROI Era Just Started.
The AI industry has reached a turning point. The question is no longer whether models can do impressive things. It’s whether they can do them at a price that makes sense.
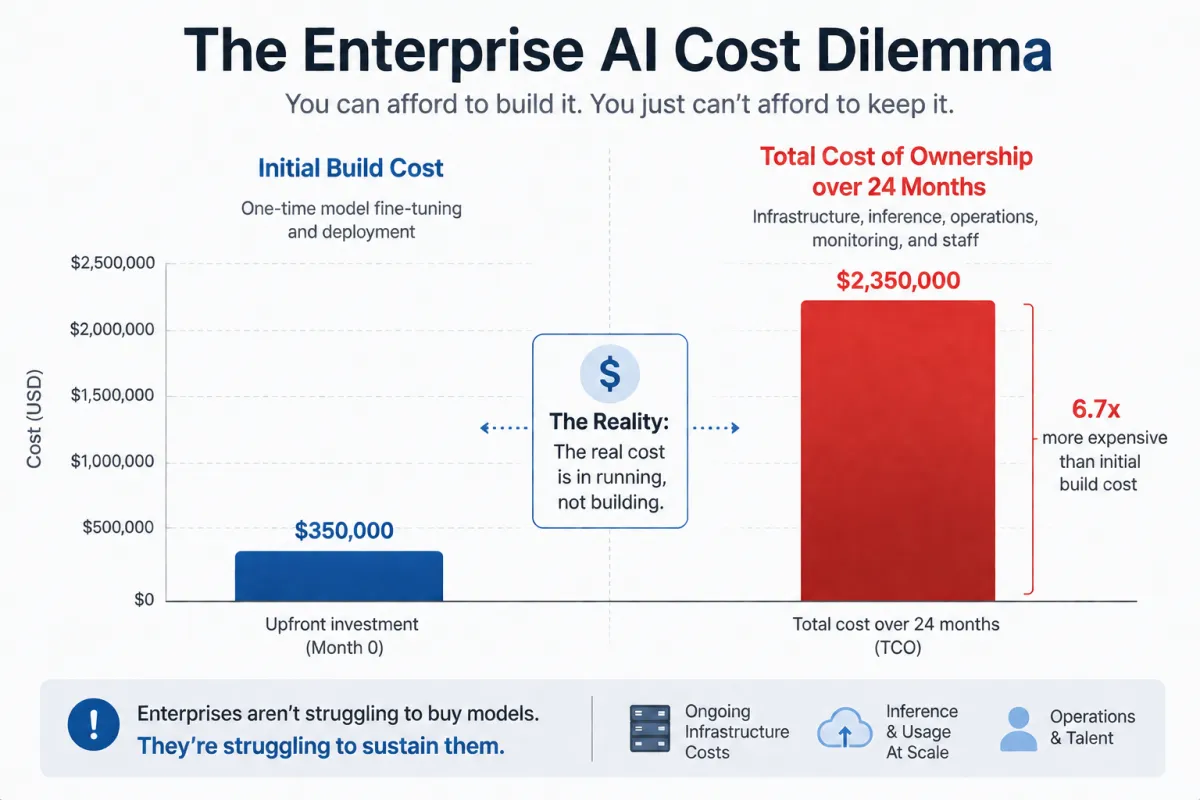
Enterprise adoption won’t scale on demos. It will scale on ROI. Hidden costs — data engineering, model monitoring, continuous retraining, inference at scale — are now surpassing initial model development costs . Total cost of ownership over 24 months routinely runs 1.8 to 2.5 times the initial build cost .
This isn’t about building better models. It’s about building sustainable businesses. The era of “spend anything to run anything” is ending. The era of “can we actually afford to run this” has begun.
P.S. OpenAI is treating its cost reduction as a trade secret. That’s the most telling signal of all. When a company won’t tell its own employees how it cut costs, the competitive advantage isn’t the model — it’s the economics. But as the Jevons paradox makes clear, cheaper tokens won’t mean smaller bills. They’ll mean more usage, more agents, and more complexity. The companies that survive this phase won’t be the ones with the cheapest tokens. They’ll be the ones that figure out how to turn token efficiency into real business outcomes.

